# 许可证
本项目采用 **GNU Affero General Public License v3.0 (AGPL-3.0)** 进行许可。
详见根目录 [`LICENSE`](./LICENSE) 文件。
# 时伴 SmartMate
> 越用越懂你的成长型 AI 排程伙伴 · 面向大学生的陪伴式日程管理平台
# 1 项目概览
## 1.1 总体介绍
时伴(SmartMate)是面向大学生的 AI 排程伙伴。通过自然语言对话管理课表与任务,更能在一次次交流中记住你的习惯、偏好和生活节奏——**越用越懂你,越排越贴心。**
核心能力包括:大规模智能排程、基于课表的任务编排、AI 驱动的"小事随口记",以及跨会话的长期记忆积累——做到:**一个伙伴,包揽生活大小事。**
本项目采用前后端分离设计,并且有一个**完整的工业化设计链路**:写功能-墨刀画页面-根据页面写接口-写后端-写前端(AI)。
## 1.2 项目解决的痛点
> **问题1:** 传统的日程平台(类似于滴答清单等)要么设置重复任务(例如每日背单词、每日刷题等),要么就需要手动设置任务,非常不方便。一旦遇到需要大规模安排任务的场景,例如期末考前半个月突击(涉及的科目多,手头的空余时间也多,每门课的任务又都不一样),就需要先手动规划好任务,再手指点个不停给它排进日程软件里面,还得思考怎样排比较合理,一旦执行出问题需要调整,又像多米纳骨牌倒了一样,连着调整一大块。
**本项目带来的解决方案1:** 采用类似于老师备课-教务处排课的"备课-排课"模式。即假如你是学校上课的老师,你先在"备课区"把这门课程的"教学"大纲排好,然后再考虑后面安排上课的事情。
拿概率论举例子,你准备给它16节课时间复习,那你就在新增任务类的区域**创建新任务类**,并设置好在第x**任务块**看xx章节的速成课,然后第x任务块是真题练习。
设置完了之后,再通过我们的排课功能(会先设计一个保证能排的算法,第二批次开发还会考虑AI介入让课排的更好),你设置一些排课的倾向(更倾向于在哪个时间点学、不想在哪个时间点学、想每天均匀推进还是快速突击等等),点一下**智能一键编排**按钮,会将课直接以黄色打底的形式嵌入日程中,确认无误后你点击正式应用日程,课才会真正被排进去。
至于调整,本项目支持在课表区域直接拖拽调整时间。
> **问题2:** 期末周没课,确实可以按照上面一样操作。那我如果不是期末复习呢,我如果想安排一些别的事情呢,比如推进项目?我平时可是有课的,而且有不少水课。传统的日程软件可没法在水课处排课,要么忘记去上水课,要么忘记任务,十分恼火。
**本项目带来的解决方案2:** 本项目支持学校课表导入,甚至还支持水课嵌入任务。在导入课表之后,本项目支持勾选某些课程为"**可嵌入任务**"状态,此时就可以配合上面的排课系统,将水课作为可用的区域,排任务进去。
> **问题3:** 那么我作为一个规划能力比较差的懒人,也能用这个项目来让自己变的充实吗?
**本项目带来的解决方案3:** 当然可以,这就是本项目接入AI的意义。聊天区域的AI将会被调教成一个日程安排的小助手,既能满足你简单的任务记录、任务查询与部分日程调整需求,又能协助你从0开始一点点制定属于你的计划。(当前版本已支持AI随口记、任务查询,以及部分日程调整的确认流;更完整的自动规划与更复杂的读写能力仍在继续迭代)
> **问题4:** 我平时会突然冒出来一个能让自己活的更舒服亦或是变得更好的小想法(例如把桌面理一下、给自己挑一件新衣服等),但是现在很忙,根本没时间做,然后等忙完了有时间了又忘记了。传统的日程软件确实能让我记录下来(比如将这个小想法记录在日程软件的四象限里面的"不重要不紧急"象限),就是太麻烦了。
>
> 还有,平时上课时,接踵而至的实验报告、小组作业等,也面临着类似的情况,既容易忘记,又懒得记录。
**本项目带来的解决方案4:** 本项目支持AI驱动的"随口记"功能。
你可以和本项目的AI助手说:"提醒我**有空的时候**给自己挑一件新衣服"(**请注意标粗的关键词**),AI助手就会自动评估这件小事的难度以及执行所需花费的时间:如果这件事很简单或者不费时,会被加入"简单不重要"的队列中;如果比较费时或者困难,就会被加入"不简单不重要"队列中。
至于突发任务,也支持使用该"随口记"功能。你可以这么说:"提醒我**下周周日之前**完成xx课程的大作业"(**请注意标粗的关键词**),AI就会自动通过**截止时间和任务量**判断是否紧急,选择将其加入"重要并紧急"或者"重要不紧急"任务队列中(这里也是借鉴了四象限设计)。并且,系统会**每经过一个固定时间,就自动调整两个任务队列中未完成任务的位置**(比如:随着DDL临近,将重要不紧急队列中的未完成任务挪到重要并紧急队列中)。
当你在空闲时(做完你的大主线之后),亦或是休息时间打开本项目,一眼就能看到这几个队列的事情,然后你就可以看心情选择做哪个,然后做完之后一划就完事。
> **问题5:** 每次打开 AI 助手,都要重新告诉它"我周三有课"、"我更喜欢早上学数学"。传统工具对你没有记忆,每次都从零开始,永远是个陌生人。
**本项目带来的解决方案5:** 时伴内置长期记忆系统,会在对话中自动抽取并积累关于你的事实与偏好(课程、习惯、目标等)。下次对话时自动召回相关记忆注入上下文,跨会话延续对你的了解,且支持全链路优雅降级——记忆检索失败不阻断正常对话。
## 1.3 项目实现的功能
1. **对用户目前时间尺度的适应。**
当前版本以学校排课节次为主,采用第1-2节、第3-4节这种时间组织方式,同时兼容首页任务管理与周课表日程编排两套视图,方便把任务管理和日程安排放在同一系统中;
目前暂未开放用户自定义时间尺度配置,当前仍以固定节次模型为主。后续会有更新计划的!
2. **导入学校课表。** 本项目后端已提供学校课表导入能力(当前主要尝试兼容CQUPT的课表格式),以便后续以课表为基底进行日程安排;前端完整导入流程入口仍在补齐。
3. **"水课"任务嵌入。** 正如上方**问题2**所言,在已导入课表的前提下,支持设置某一门你想拿来干其它事情的课为"可嵌入任务"状态,此时这门课所占据的时间区域就是可以嵌入任务的了,但是仍然有区别于其它完全空白的时间区域,便于真正安排适合在嘈杂环境下做的事情。
4. **设置某一任务类,并配置其编排参数。** 正如上方**问题1**所言,用户可以先设置一个大的任务类(例如概率论复习、算法进阶计划等等),再为这个任务类配置任务块内容、起止日期、总节数、编排策略等信息,方便后续的日程编排。
5. **一键编排任务。** 结合算法与用户配置,将任务基于导入的课表和任务类设置先生成预览结果;确认无误后,再正式应用到日程中。
6. **AI随口记与任务查询。** 正如问题4所言,当前版本支持通过AI随手记录一些大小事,也支持按象限、关键词、截止时间等维度查询任务;部分日程调整能力已接入确认流。
7. **多用户。** 本系统可支持多个用户同时使用,并且记录AI对话、编排任务的Token使用情况等,并进行限额。
8. **四象限任务与日程编排并行管理。** 首页的四象限任务用于日常待办管理;
而周课表中的课程与排入日程的任务类则用于日程编排,两类信息分别展示、相互配合。
9. **完成任务状态的恢复。** 当前首页四象限任务支持将"已完成"恢复为"未完成"状态。
用户只需要在队列中找到该任务,然后再次点击对应状态按钮即可完成恢复。
至于日程侧,当前主要支持删除、解除安排与预览后再正式应用,其它更完整的恢复能力仍在后续迭代中。
10. **长期记忆积累。** 系统在对话中自动抽取用户相关事实与偏好,跨会话召回并注入对话上下文,实现"越用越懂你"的个性化体验。支持结构化检索 + 向量召回双路召回,全链路优雅降级。
# 2 产品逻辑与设计
## 2.1 业务流程图
当前版本主业务闭环如下,重点体现“首页任务管理 / AI 助手 / 日程编排 / 长期记忆”四条主线如何互相联动:
```mermaid
flowchart TD
A["用户进入系统"] --> B{"是否已登录"}
B -- "否" --> C["/auth 登录 / 注册"]
C --> D["进入主工作区"]
B -- "是" --> D
D --> E{"选择功能入口"}
E -- "首页 /dashboard" --> F["查看四象限任务 + 今日日程"]
F --> G["创建任务 / 完成任务 / 恢复任务"]
G --> H["首页持续展示最新待办状态"]
E -- "AI 助手 /assistant" --> I["输入自然语言需求"]
I --> J["newAgent 统一 graph"]
J --> K{"路由结果"}
K -- "随口记 / 任务查询" --> L["写入任务或返回查询结果"]
K -- "智能编排 / 日程调整" --> M["plan / confirm / execute / deliver"]
K -- "普通问答" --> N["直接回复用户"]
M --> O["返回排程结果卡片"]
O --> P["查看结构化预览并继续微调"]
P --> Q{"如何收口"}
Q -- "暂存" --> R["保存到 Redis 运行态"]
Q -- "正式应用" --> S["写入正式课表"]
L --> T["更新任务列表 / 对话历史"]
N --> U["沉淀对话历史"]
E -- "日程中心 /schedule" --> V["查看周课表与任务类"]
V --> W["新建任务类 / 删除任务块 / 单选或批量多选"]
W --> X["智能粗排 / 批量粗排"]
X --> Y["前端预览态拖拽调整"]
Y --> Z["正式应用到日程"]
S --> AA["周课表更新"]
Z --> AA
H --> AB["用户继续使用系统"]
T --> AB
U --> AB
AA --> AB
AB --> AC["异步事件:聊天持久化 / Outbox / Memory 抽取"]
AC --> AD["长期记忆写入与更新"]
AD --> AE["下一轮对话自动召回 memory_context"]
AE --> I
```
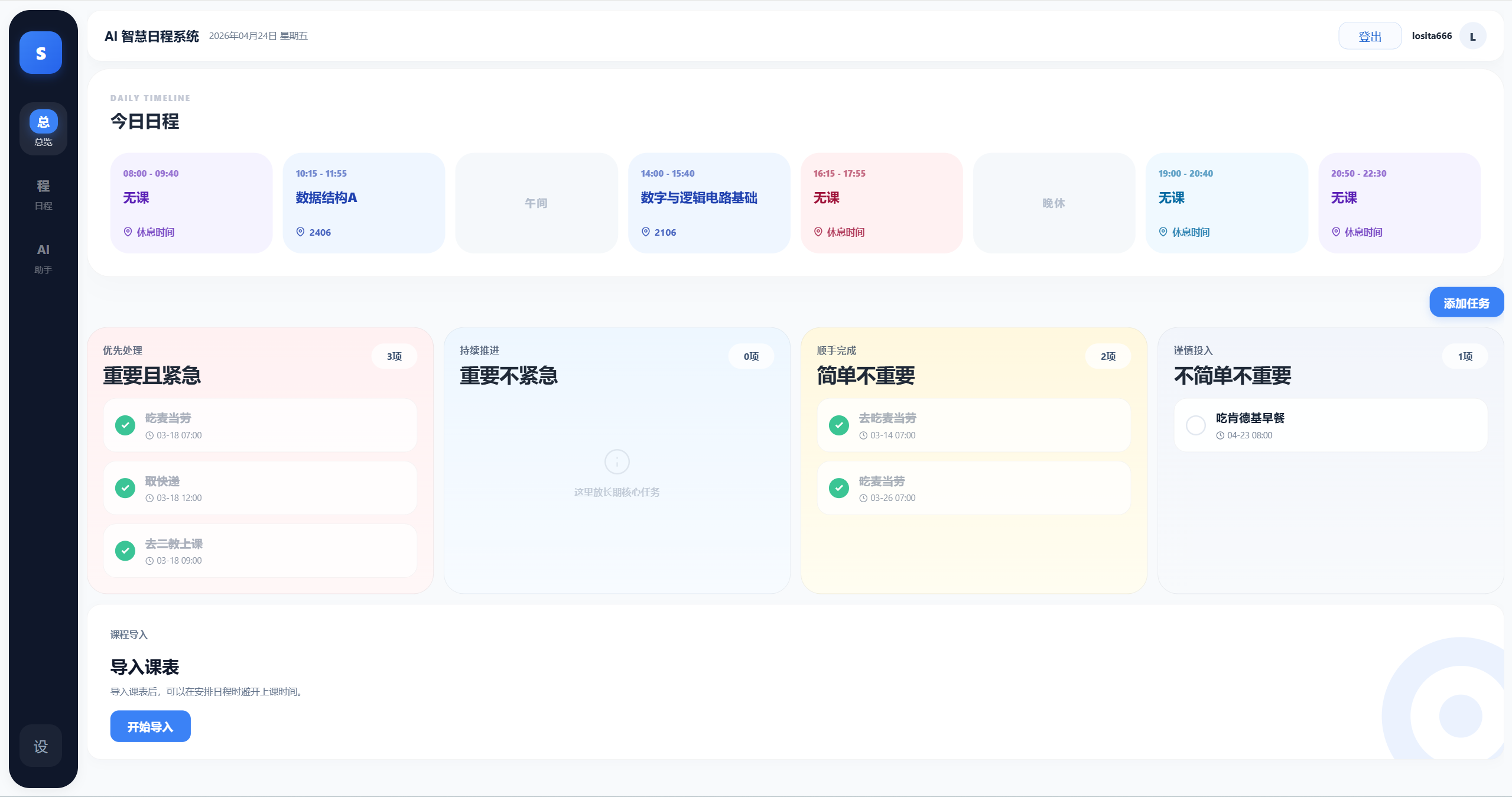
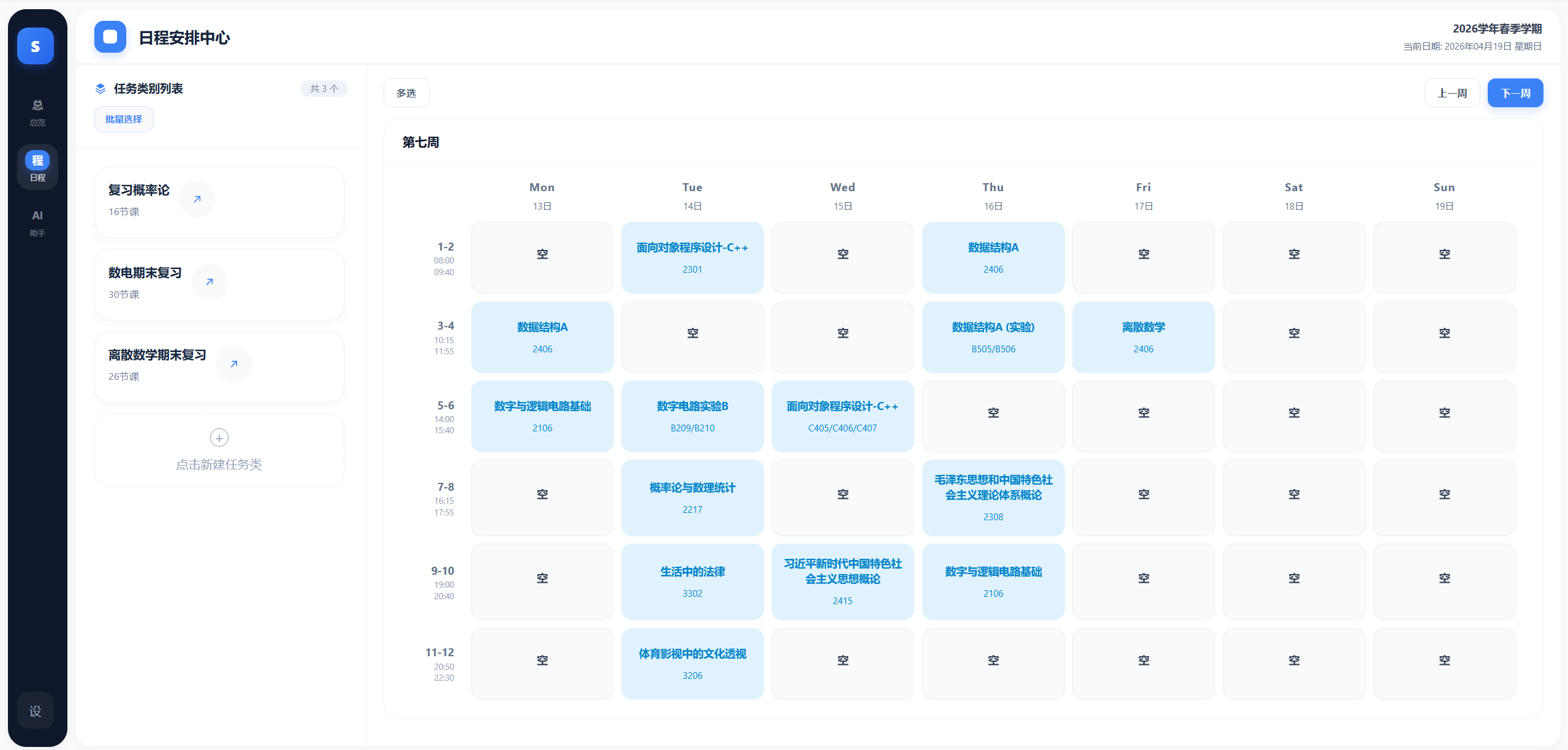
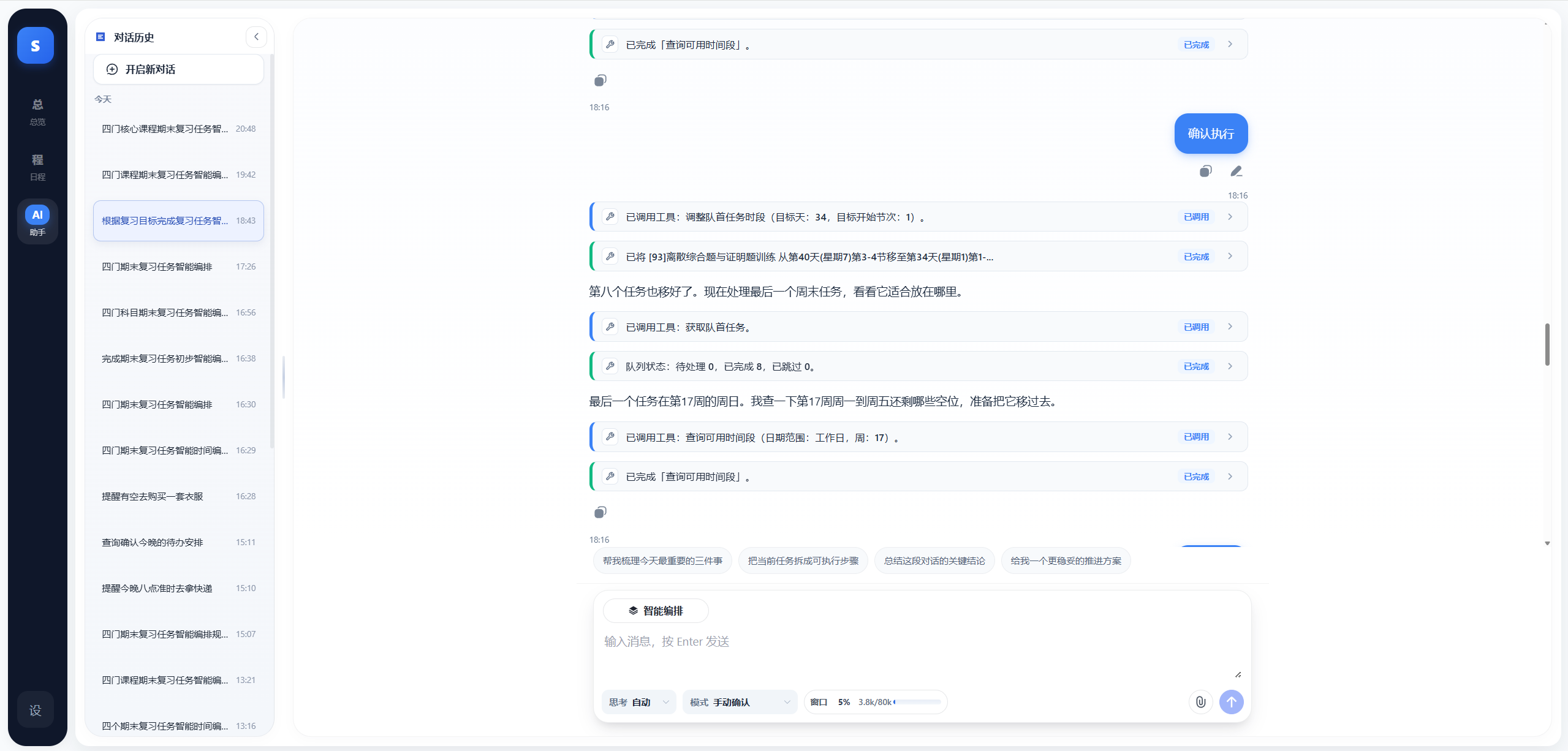
## 2.2 页面展示
# 3 后端数据架构
## 3.1 ER图
PS:此图截至版本v0.3.3

## 3.2 核心表结构
其实每个表都很核心。在此展示它们的创建语句:
```sql
CREATE TABLE `agent_chats`
(
`id` int NOT NULL AUTO_INCREMENT,
`user_id` int DEFAULT NULL,
`message_content` text COMMENT '用户或AI的话',
`role` varchar(255) DEFAULT NULL COMMENT 'user / assistant',
`tokens_consumed` int DEFAULT '0' COMMENT '单次消耗,用于累加到 users 表',
`created_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_agent_chats_id` (`id`),
KEY `user_id` (`user_id`),
CONSTRAINT `agent_chats_ibfk_1` FOREIGN KEY (`user_id`) REFERENCES `users` (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_0900_ai_ci
CREATE TABLE `courses`
(
`id` int NOT NULL AUTO_INCREMENT,
`user_id` int DEFAULT NULL,
`name` varchar(255) NOT NULL,
`location` varchar(255) DEFAULT NULL,
`is_filler` tinyint(1) DEFAULT '0',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_courses_id` (`id`),
KEY `user_id` (`user_id`),
CONSTRAINT `courses_ibfk_1` FOREIGN KEY (`user_id`) REFERENCES `users` (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_0900_ai_ci
CREATE TABLE `schedule_events`
(
`id` int NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`name` varchar(255) NOT NULL COMMENT '课程或任务名称',
`location` varchar(255) DEFAULT '' COMMENT '地点 (教学楼/会议室)',
`type` enum ('course','task') NOT NULL COMMENT '日程类型',
`rel_id` int DEFAULT NULL COMMENT '关联原始数据ID (如教务系统的课程ID)',
`can_be_embedded` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否允许在此时段嵌入其他任务',
`created_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
`updated_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`start_time` datetime DEFAULT NULL COMMENT '任务开始的绝对时间',
`end_time` datetime DEFAULT NULL COMMENT '任务结束的绝对时间',
PRIMARY KEY (`id`),
KEY `idx_user_events` (`user_id`),
KEY `idx_user_endtime` (`user_id`, `end_time` DESC),
CONSTRAINT `fk_event_user` FOREIGN KEY (`user_id`) REFERENCES `users` (`id`) ON DELETE CASCADE
) ENGINE = InnoDB
AUTO_INCREMENT = 148
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_0900_ai_ci
CREATE TABLE `schedules`
(
`id` int NOT NULL AUTO_INCREMENT,
`event_id` int NOT NULL COMMENT '关联元数据ID',
`user_id` int NOT NULL COMMENT '冗余UID方便直接查询',
`week` int NOT NULL COMMENT '周次 (1-25)',
`day_of_week` int NOT NULL COMMENT '星期 (1-7)',
`section` int NOT NULL COMMENT '原子化节次 (1-12)',
`embedded_task_id` int DEFAULT NULL COMMENT '若为水课嵌入,记录具体的任务项ID',
`status` enum ('normal','interrupted') DEFAULT 'normal' COMMENT '状态: 正常/因故中断',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_slot_atomic` (`user_id`, `week`, `day_of_week`, `section`),
KEY `idx_event_id` (`event_id`),
KEY `fk_embedded_task` (`embedded_task_id`),
CONSTRAINT `fk_embedded_task` FOREIGN KEY (`embedded_task_id`) REFERENCES `task_items` (`id`) ON DELETE SET NULL,
CONSTRAINT `fk_schedule_event` FOREIGN KEY (`event_id`) REFERENCES `schedule_events` (`id`) ON DELETE CASCADE,
CONSTRAINT `fk_schedule_user` FOREIGN KEY (`user_id`) REFERENCES `users` (`id`) ON DELETE CASCADE
) ENGINE = InnoDB
AUTO_INCREMENT = 214
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_0900_ai_ci
CREATE TABLE `task_classes`
(
`id` int NOT NULL AUTO_INCREMENT,
`user_id` int DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`mode` enum ('auto','manual') DEFAULT NULL,
`start_date` date DEFAULT NULL,
`end_date` date DEFAULT NULL,
`total_slots` int DEFAULT NULL COMMENT '分配的总节数',
`allow_filler_course` tinyint(1) DEFAULT '1',
`strategy` enum ('steady','rapid') DEFAULT NULL,
`excluded_slots` json DEFAULT NULL COMMENT '不想要的时段切片',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_task_classes_id` (`id`),
KEY `idx_task_classes_user_id` (`user_id`),
CONSTRAINT `task_classes_ibfk_1` FOREIGN KEY (`user_id`) REFERENCES `users` (`id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 15
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_0900_ai_ci
CREATE TABLE `task_items`
(
`id` int NOT NULL AUTO_INCREMENT,
`category_id` int DEFAULT NULL,
`content` text,
`embedded_time` json DEFAULT NULL COMMENT '目标时间{date,section_from,section_to}',
`status` int DEFAULT NULL COMMENT '1:未安排, 2:已应用',
`order` int DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_task_items_id` (`id`),
KEY `task_items_ibfk_1` (`category_id`),
CONSTRAINT `task_items_ibfk_1` FOREIGN KEY (`category_id`) REFERENCES `task_classes` (`id`) ON DELETE CASCADE
) ENGINE = InnoDB
AUTO_INCREMENT = 43
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_0900_ai_ci
CREATE TABLE `tasks`
(
`id` int NOT NULL AUTO_INCREMENT,
`user_id` int DEFAULT NULL,
`title` varchar(255) NOT NULL,
`priority` int DEFAULT NULL,
`is_completed` tinyint(1) DEFAULT '0',
`deadline_at` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_tasks_id` (`id`),
KEY `idx_user_id` (`user_id`),
CONSTRAINT `tasks_ibfk_1` FOREIGN KEY (`user_id`) REFERENCES `users` (`id`),
CONSTRAINT `chk_priority` CHECK ((`priority` in (1, 2, 3, 4)))
) ENGINE = InnoDB
AUTO_INCREMENT = 23
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_0900_ai_ci
CREATE TABLE `users`
(
`id` int NOT NULL AUTO_INCREMENT,
`username` varchar(255) NOT NULL,
`password` varchar(255) NOT NULL,
`phone_number` varchar(255) DEFAULT NULL,
`token_limit` int DEFAULT '100000',
`token_usage` int DEFAULT '0',
`last_reset_at` timestamp NULL DEFAULT NULL COMMENT '上次周用量重置时间',
PRIMARY KEY (`id`),
UNIQUE KEY `username` (`username`),
UNIQUE KEY `uk_users_id` (`id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 4
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_0900_ai_ci
```
# 4 接口契约
## 4.1 核心API列表(ApiFox)
链接如下:https://oqg5uiubh0.apifox.cn
## 4.2 Agent可调用的工具定义
以下定义基于当前代码实现(`backend/newAgent/tools/registry.go` + `backend/cmd/start.go` 注入),不是规划态文档。
### 4.2.1 调用契约
1. `tool_call` 必须是单个对象,格式为:
```json
{"tool_call":{"name":"工具名","arguments":{}}}
```
2. 日程写工具默认走 `confirm` 确认闸门(`always_execute=true` 时可跳过确认)。
3. 非日程写工具(如 `quick_note_create`、`query_tasks`、`web_search`、`web_fetch`)走 `continue + tool_call`。
4. 当前每轮只允许调用一个工具,不支持同轮批量工具数组。
### 4.2.2 工具清单(当前版本)
| 工具名 | 类型 | 是否需确认 | 是否依赖 ScheduleState | 核心参数 | 作用与约束 |
| --- | --- | --- | --- | --- | --- |
| `get_overview` | 读 | 否 | 是 | 无 | 获取规划窗口总览(任务视角,全量返回) |
| `query_range` | 读 | 否 | 是 | `day`(必填), `slot_start`, `slot_end` | 查询某天/某时段占用详情 |
| `query_available_slots` | 读 | 否 | 是 | `span`, `duration`, `limit`, `day_scope`, `week_filter` 等 | 查询候选空位池(纯空位优先,不足再补可嵌入位) |
| `query_target_tasks` | 读 | 否 | 是 | `status`, `category`, `task_ids`, `enqueue` 等 | 过滤任务集合,可选自动入队供后续队列工具处理 |
| `queue_pop_head` | 读 | 否 | 是 | 无 | 取出/复用当前队首任务(一次只处理一个) |
| `queue_status` | 读 | 否 | 是 | 无 | 查看队列状态(pending/current/completed/skipped) |
| `get_task_info` | 读 | 否 | 是 | `task_id`(必填) | 查询单任务详细信息 |
| `place` | 写 | 是 | 是 | `task_id`, `day`, `slot_start`(均必填) | 将待安排任务预排到指定位置 |
| `move` | 写 | 是 | 是 | `task_id`, `new_day`, `new_slot_start`(均必填) | 仅允许移动 `suggested`;`existing` 不可 `move` |
| `swap` | 写 | 是 | 是 | `task_a`, `task_b`(均必填) | 交换两个已落位任务,要求时长一致 |
| `batch_move` | 写 | 是 | 是 | `moves[]`(必填) | 原子批量移动,当前最多 2 条,任一冲突整批回滚 |
| `queue_apply_head_move` | 写 | 是 | 是 | `new_day`, `new_slot_start`(均必填) | 移动当前队首并自动出队,不接受 `task_id` |
| `queue_skip_head` | 队列控制 | 否 | 是 | `reason` | 跳过当前队首并标记 `skipped`(不改日程) |
| `spread_even` | 写 | 是 | 是 | `task_ids`(必填,兼容 `task_id`) | 在任务集合内做均匀铺开,按筛选条件原子落地 |
| `min_context_switch` | 写 | 是 | 是 | `task_ids`(必填,兼容 `task_id`) | 减少上下文切换重排;仅在用户明确允许打乱顺序时可执行 |
| `unplace` | 写 | 是 | 是 | `task_id`(必填) | 取消任务落位并恢复待安排状态 |
| `quick_note_create` | 读写混合(业务写入) | 否 | 否 | `title`(必填), `deadline_at`, `priority_group` | 记录随口记任务,支持中文相对时间;优先级可自动推断 |
| `query_tasks` | 读 | 否 | 否 | `quadrant`, `keyword`, `deadline_before/after`, `limit` 等 | 按象限/关键词/时间边界查询任务 |
| `web_search` | 读 | 否 | 否 | `query`(必填), `top_k`, `domain_allow`, `recency_days` | Web 检索,返回结构化标题/摘要/URL;未启用时优雅返回错误 observation |
| `web_fetch` | 读 | 否 | 否 | `url`(必填), `max_chars` | 抓取并清洗网页正文;服务不可用时优雅返回错误 observation |
### 4.2.3 当前实现中的关键规则
1. `min_context_switch` 有顺序护栏:未授权“允许打乱顺序”会被后端拦截并返回拒绝结果。
2. `batch_move` 有安全上限:当前最多支持 2 条移动请求,超出建议走队列化逐项处理。
3. `quick_note_create` 和 `query_tasks` 不依赖 `ScheduleState`,由执行层注入 `_user_id` 后可直接调用。
4. `web_search`/`web_fetch` 失败不会打断主链路,都会回传结构化错误 observation 给模型继续决策。
# 5 后端实现
## 5.1 技术栈
| **分类** | **选用技术** | **在时伴中的应用场景** |
| ----------------- | ---------------- | ------------------------------------------------------------ |
| **Web 框架** | **Gin** | 负责全站 API 的路由分发,处理任务增删改查及智能排程的请求。 |
| **持久层数据库** | **MySQL 8.0** | 存储用户、任务、课表及日程运行图(Schedules)的核心数据。 |
| **ORM 框架** | **GORM** | 用于简化 Go 与数据库的交互,利用事务处理 `Apply` 接口的原子性操作。 |
| **高性能缓存** | **Redis** | 缓存用户的周日程视图(避免频繁扫表)、存储 Token 临时限额、实现分布式锁防止重复排程。 |
| **消息队列** | **Outbox + Kafka** | **可靠异步解耦**:请求主链路先写 Outbox,后台再投递 Kafka 并消费落库,既降低首字延迟又避免消息瞬时丢失。 |
| **AI 编排框架** | **Eino** | 作为 AI Agent 的大脑,根据排程策略(Steady/Rapid)计算任务与水课的嵌入逻辑。 |
| **身份认证** | **JWT** | 实现无状态登录,将 `user_id` 封装在 Token 中,确保数据的用户隔离。 |
| **配置管理** | **Viper** | 管理数据库、Redis、Kafka 的连接参数,支持多环境(开发/生产)切换。 |
| **API 文档/调试** | **Apifox** | 维护接口协议,进行前后端联调及自动化测试。 |
| **日志监控** | **Zap / Logrus** | 记录系统运行状态,特别是 Kafka 消费失败或 AI 接口超时的错误日志。 |
## 5.2 架构图
PS:截至v0.3.3。其中黑色箭头为请求数据链路,绿色箭头为返回数据,虚线箭头为控制流。
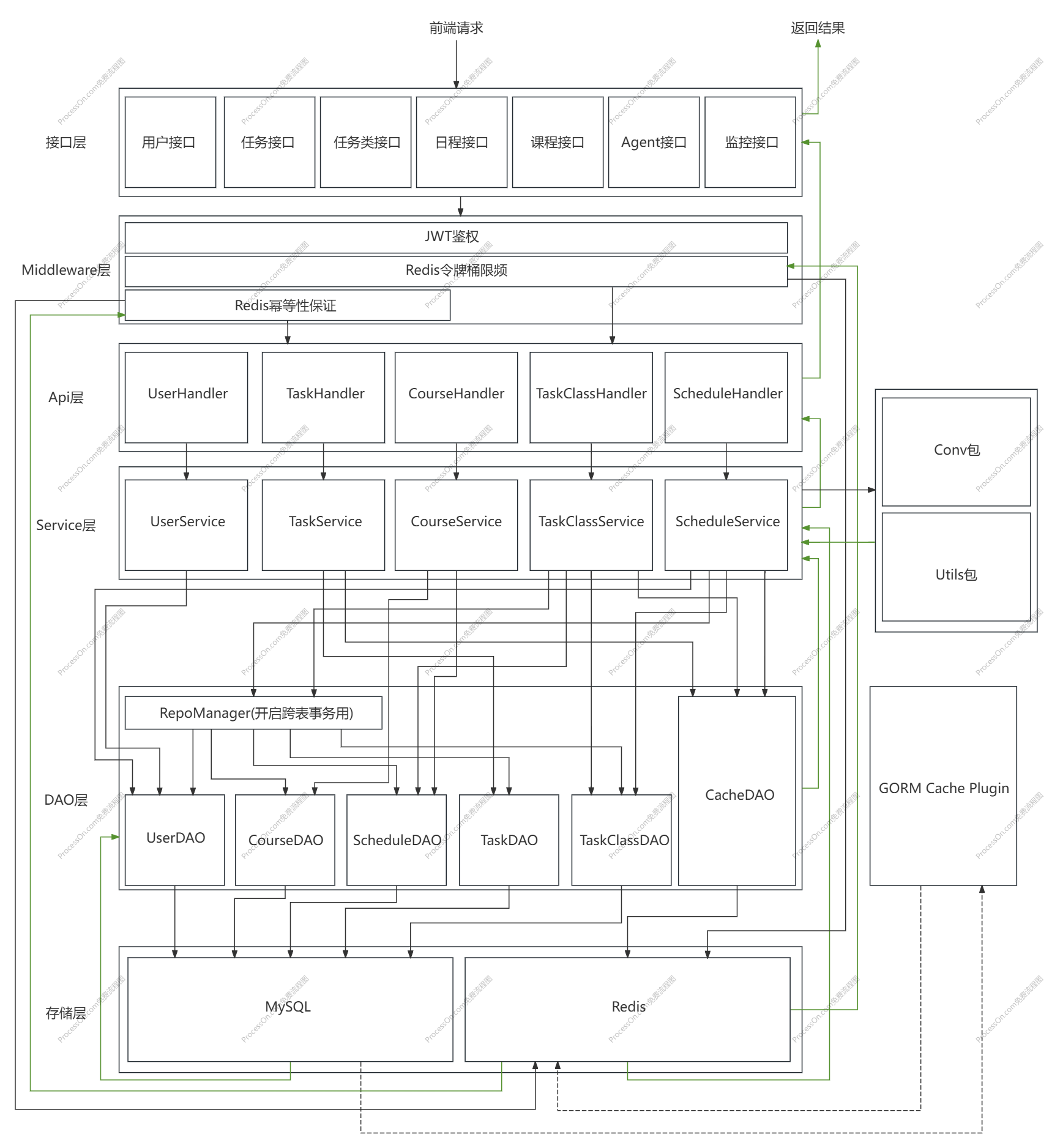
## 5.3 核心算法
### 5.3.1 智能排课算法
本系统采用 **“原子化时间网格(Atomic TimeGrid)”** 架构,实现了针对大学生复杂课表环境的智能任务填充。算法核心分为 **“沙盘模拟”、“边界感知探测”** 与 **“逻辑位移步进”** 三大模块。
**1. 原子化时间沙盘 (Grid Sandboxing)**
算法首先将物理时间窗口(StartDate 到 EndDate)抽象为一个三维矩阵 $Grid[Week][Day][Section]$。
- **多维状态标记**:每个格子(Slot)是携带 `Status` 和 `EventID` 的 `slotNode` 节点。
- **优先级注水(Hydration)**:
1. **Blocked(屏蔽区)**:根据用户配置的 `ExcludedSlots` 强制锁定,优先级最高。
2. **Filler(嵌入区)**:识别“水课”,标记为可利用资源。
3. **Occupied(占用区)**:映射既有硬核课程,确保调度不产生物理冲突。
**2. 边界感知探测 (Boundary-Sensing Detection)**
为了解决“任务块跨课分身”的 Bug,算法引入了 **EventID 校验机制**。
- **容器自适应长度**:当算法探测到一个 `Filler` 槽位时,会向后贪心扫描,只有当相邻槽位的 `EventID` 相同且同为 `Filler` 时,才允许任务块拉伸。
- **逻辑闭环**:这保证了任务块(TaskItem)要么完美嵌入单门水课,要么占据空地,绝不会出现一个任务横跨两门不同课程的情况。
**3. 稳扎稳打:逻辑位移步进 (Logical-Offset Skipping)**
在 `Steady`(稳扎稳打)模式下,为了实现负载均衡,算法弃用了传统的“物理时间跳跃”,改用 **“逻辑坑位跳跃”**。
$$Gap = \frac{TotalAvailableSlots - (TaskCount \times 2)}{TaskCount + 1}$$
- **物理跳跃(旧版/错误)**:直接 $Time + Gap$,容易因遇到屏蔽时段或硬核课而导致游标溢出,从而“吞掉”后续任务。
- **逻辑跳跃(现行/优化)**:调用 `skipAvailableSlots` 函数,在 Grid 中沿时间轴向后数出 $Gap$ 个**真正可用**的格子作为下一个起点。
- **价值**:确保了在有限的 **2C4G** 服务器资源下,任务能像“等距列队”一样均匀分布在学期空隙中。
------
**🛠️ 算法运行流程**
1. **Build**:调用 `buildTimeGrid`,将数据库的离散 `Schedules` 映射为内存状态网格。
2. **Count**:统计当前窗口内所有 `Free` 与 `Filler` 的原子位总数。
3. **Allocate**:
- 通过 `FindNextAvailable` 锁定首个合法坑位。
- 进行 **容器探测** 决定任务块长度。
- 执行 `skipAvailableSlots` 寻找下一个负载均衡点。
4. **Preview**:输出 DTO 到前端,标记 `status: "suggested"` 供用户预览高亮。
------
**⚡ 性能表现 (Optimization)**
- **时间复杂度**:$O(W \times D \times S)$,其中 $W$ 为任务类跨度周数。在处理典型的 16 周排程时,计算量仅在数千次操作级别,单机响应达毫秒级。
- **空间复杂度**:由于采用了按需创建周 Map 的策略,内存占用随任务跨度动态伸缩,极大地减轻了重庆邮电大学校园服务器环境下的 GC 压力。
------
**数据回填**
在执行完上述算法后,将任务块分成两类数据:
1. 需要新建`ScheduleEvent`的,插入纯空闲时段的数据;
2. 直接嵌入现有课程中的任务块;
然后分别调用不同的业务逻辑,开启大事务,批量插入,使得只需要连接2次数据库,并且若插入出错,支持批量回滚,不会存在任何脏数据。
## 5.4 Agent范式实现细节
### 1) 统一入口与 graph 主链
```mermaid
flowchart TD
A["/api/v1/agent/chat
接收 user_message / thinkingMode / extra"] --> B["AgentService.runNewAgentGraph"]
B --> C["确保会话存在
加载或创建 RuntimeState"]
C --> D["恢复或构建 ConversationContext
并预取 memory pinned block"]
D --> E["先持久化本轮 user message"]
E --> F["组装 AgentGraphRunInput
Chat/Deliver 用 Pro
Plan/Execute 用 Max"]
F --> G["RunAgentGraph"]
G --> H["START -> chat"]
H --> I{"chat 决定下一步"}
I -- "简单回复 / 深答" --> J["chat 节点内直接完成"]
I -- "复杂规划" --> K["plan"]
I -- "直接执行" --> L["execute"]
I -- "execute 前需要粗排" --> M["rough_build"]
I -- "已有 pending interaction" --> N["chat 先做 resume"]
K --> O["confirm / rough_build / execute / deliver / interrupt"]
L --> P["execute / confirm / order_guard / deliver / interrupt"]
M --> Q["execute / order_guard / deliver / interrupt"]
N --> O
N --> P
J --> R["deliver 或 END"]
O --> S["deliver"]
P --> S
Q --> S
S --> T["END"]
```
### 2) `chat` 节点路由与恢复
```mermaid
flowchart TD
A["进入 chat 节点"] --> B{"存在 pending interaction?"}
B -- "是" --> C["handleChatResume
不再调路由 LLM"]
C --> D{"pending 类型"}
D -- "ask_user" --> E["ResumeFromPending
发 resumed 状态"]
E --> F["恢复原 phase
继续 plan 或 execute"]
D -- "confirm + accept" --> G["恢复 PendingTool
Phase=executing"]
D -- "confirm + reject(计划)" --> H["RejectPlan
回 planning"]
D -- "confirm + reject(工具)" --> I["回 executing 改策略"]
D -- "interaction_id 不匹配" --> J["stale_resume
本轮结束"]
B -- "否" --> K{"上一轮是否 completed?"}
K -- "是" --> L["写 execute_loop_closed marker
ResetForNextRun"]
K -- "否" --> M["直接构建路由消息"]
L --> M
M --> N["一次快速路由 LLM
BuildChatRoutingMessages"]
N --> O{"route"}
O -- "direct_reply" --> P["chat 内直接流式回复
Phase=chatting -> END"]
O -- "deep_answer" --> Q["二次 deep answer 调用
可开启 thinking -> END"]
O -- "plan" --> R["Phase=planning"]
O -- "execute" --> S["StartDirectExecute
写 AllowReorder / ExecuteThinking"]
S --> T{"NeedsRoughBuild?"}
T -- "是" --> U["rough_build"]
T -- "否" --> V["execute"]
R --> W["plan"]
```
### 3) `plan / confirm / rough_build` 链路
```mermaid
flowchart TD
A["Phase=planning -> plan 节点"] --> B["LLM 生成 PlanDecision
可开启 thinking"]
B --> C{"action"}
C -- "continue" --> A
C -- "ask_user" --> D["OpenAskUserInteraction
graph -> interrupt"]
C -- "done" --> E["FinishPlan
写 pinned blocks:
current_plan / current_step"]
E --> F{"AlwaysExecute?"}
F -- "否" --> G["confirm"]
G --> H["EmitConfirmRequest
OpenConfirmInteraction(type=plan)"]
H --> I["interrupt 等用户"]
I --> J["用户下一轮回复 -> chat resume"]
J --> K{"accept / reject"}
K -- "accept" --> L{"NeedsRoughBuild?"}
K -- "reject" --> A
F -- "是" --> M["自动展示计划摘要
ConfirmPlan -> PhaseExecuting"]
M --> L
L -- "否" --> N["execute"]
L -- "是" --> O["rough_build"]
O --> P["调用 RoughBuildFunc
写回 ScheduleState"]
P --> Q["写 rough_build_done pinned block
标记 HasScheduleChanges"]
Q --> R{"仍有真实 pending?"}
R -- "是" --> S["Abort -> deliver"]
R -- "否" --> T{"需要继续微调?"}
T -- "是" --> N
T -- "否" --> U["Done -> deliver"]
```
### 4) `execute / confirm / order_guard` 链路
```mermaid
flowchart TD
A["Phase=executing -> execute 节点"] --> U{"NextRound 成功?"}
U -- "否" --> V["Exhaust -> deliver"]
U -- "是" --> B{"有 PendingConfirmTool?"}
B -- "是" --> C["直接执行已确认写工具"]
B -- "否" --> D["BuildExecuteMessages
LLM 产出 ExecuteDecision"]
C --> E["写 observation / 更新 ScheduleState"]
D --> F{"action"}
F -- "continue + tool_call" --> G["每轮只调用 1 个工具"]
G --> H{"写工具且需要确认?"}
H -- "是" --> I["PendingConfirmTool -> confirm"]
I --> J["EmitConfirmRequest
OpenConfirmInteraction(type=execute)"]
J --> K["interrupt 等用户"]
K --> L["用户 accept -> chat resume -> execute"]
H -- "否" --> M["写 observation
继续 execute 循环"]
F -- "continue 无工具" --> M
F -- "ask_user" --> N["OpenAskUserInteraction
interrupt 等用户"]
F -- "next_plan" --> O["推进 current_step
写 execute_step_advanced marker"]
O --> P{"还有后续计划?"}
P -- "是" --> M
P -- "否" --> Q["Done -> deliver"]
F -- "done" --> R{"AllowReorder?"}
R -- "false" --> S["order_guard
校验 suggested 相对顺序"]
S --> T["自动复原或保守放行"]
T --> Q
R -- "true" --> Q
F -- "abort" --> Q
```
### 5) `interrupt / deliver / 状态持久化` 链路
```mermaid
flowchart TD
A["plan / execute / confirm 产生 pending"] --> B["interrupt"]
B --> C{"pending 类型"}
C -- "ask_user" --> D["把 DisplayText 当 assistant 文本输出"]
C -- "confirm" --> E["不重复发确认卡片
仅发 waiting status"]
D --> F["interrupt -> END"]
E --> F
F --> G["saveAgentState"]
G --> H["用户下一轮输入
重新从 chat resume"]
I["任务正常完成 / abort / exhausted"] --> J["deliver"]
J --> K["GenerateDeliverSummary
LLM 失败则降级机械总结"]
K --> L{"completed 且有日程变更?"}
L -- "是" --> M["EmitScheduleCompleted"]
L -- "否" --> N["跳过排程完毕卡片"]
M --> O["输出最终总结"]
N --> O
O --> P{"terminal_status=completed?"}
P -- "是" --> Q["WriteSchedulePreview
只写结果态工作区"]
P -- "否" --> R["跳过排程预览写入"]
Q --> S["deliver 后 saveAgentState"]
R --> S
S --> T["graph 返回 service
发布 AgentStateSnapshot(outbox)"]
T --> U["EmitDone + 异步生成会话标题"]
```
## 5.5 长期记忆系统
时伴的长期记忆系统采用**同步读 + 异步写**架构,确保对话体验不被记忆写入拖慢。
### 写路径(异步)
```
用户消息 → 聊天落库(同事务写 Outbox) → Kafka 投递 memory.extract.requested 事件
→ 幂等入队 memory_jobs → Worker 抢占执行 → LLM 抽取事实
→ 去重决策(ADD/UPDATE/DELETE/NONE) + UUID 映射防幻觉 → 持久化 memory_items
```
关键设计:
1. **Outbox 保证不丢消息**:聊天持久化与事件投递在同一事务内,失败整体回滚,由 Outbox 重试。
2. **去重决策状态机**:LLM 对抽取的事实判断是新增、更新、删除还是跳过,避免重复记忆。
3. **UUID 映射**:为每条记忆分配唯一 ID,LLM 引用时必须使用该 ID,防止幻觉篡改。
### 读路径(同步)
```
用户消息到达 → injectMemoryContext
→ 先读 Redis 预取缓存并注入 memory_context(上一轮检索结果,首字节零等待)
→ 后台完整检索:结构化检索(按用户/类别过滤) + 向量召回(Milvus) + 重排序
→ 渲染后的最新结果经 channel 交给 Plan/Execute 节点消费,同时回写 Redis
→ 作为下一轮 Chat 节点的预取记忆继续接力 → LLM 生成回复
```
关键设计:
1. **Redis 接力预取**:本轮 Chat 先消费上一轮写入 Redis 的记忆预取缓存,保证首字节几乎不受完整检索耗时影响;后台再把最新检索结果通过 channel 交给 Plan/Execute,并顺手回写 Redis,形成“上一轮服务下一轮”的接力链路。
2. **双路召回**:完整检索阶段仍采用结构化检索 + 向量召回的混合模式,先保证精确过滤,再补足语义相关性,最后统一重排序取 Top-K。
3. **优雅降级**:Redis 未命中、后台检索失败、短应答跳过检索等情况都不会阻断主链路;最差也只是本轮不注入记忆,而不是把对话打挂。
# 6 前端实现
当前前端位于 `frontend/` 目录,已经形成一个可独立运行的 Vue 单页应用,并且前端入口目前呈现为“两条主线并存”:
1. `/assistant`:承接 `newAgent` 对话、确认、时间线、排程结果卡片与微调链路。
2. `/schedule`:承接传统课表中心、任务类侧栏、粗排预览、拖拽调整与正式应用。
## 6.1 当前前端技术栈与整体结构
技术栈如下:
| 分类 | 当前选型 | 说明 |
| --- | --- | --- |
| 前端框架 | Vue 3 | 统一使用 Composition API 与 `